This blog is heavily inspired by the CoALA paper, give it a read its awesome!
You can find the complete code here Colab
Introduction
Large Language Models (LLMs) have demonstrated remarkable capabilities in language understanding, reasoning, and generation. However, in their standard form, these models lack the ability to remember past interactions or evolve based on experience (essentially stateless). This limitation has led to the development of Agents that extend the capabilities of these foundation models by incorporating additional modules that enable interaction with environments, retention of information, and potentially improvements.
Why is Memory so important?
"Without memory, there is no culture. Without memory, there would be no civilization, no society, no future." - Elie Wiesel
Memory isn't just a technical feature, it's the cornerstone of intelligence itself. Without memory, each interaction exists in isolation, preventing the development of context aware responses and continuous improvement.
In this blog we'll explore how to overcome these challenges and build AI systems that can not only remember but learn and evolve from their experiences. We'll examine both Short term memory (STM) as well as Long term memory (LTM) and dive deeper into LTM including semantic, episodic and procedural memory. We'll dive into practical implementations for each type of memory.
Self Evolution in LLM based Agents
Before we dig deeper into memory lets take a step back and see why is memory so crucial. As discussed earlier, without memory each interaction between the user and the language model happens in isolation so unless we fine-tune the weights of model for each request we won't be able to improve or 'evolve' the AI. This is where memory comes, we can improve the output of the model by leveraging past experiences and potentially steer the output according to user's requirement.
Self evolution refers to the ability of AI systems to improve themselves through autonomous learning and adaptation. Unlike traditional AI systems that require explicit retraining or reprogramming, self-evolving agents can continuously enhance their capabilities through interaction with their environment and reflection on past experiences. We can implement self evolution through a combination of STM and LTM.
Memory in LLM based Agents
Short-term Memory
STM or working memory takes the form of conversation history or recent interactions that are included in the context window of the LLM. This allows the agent to maintain coherence within a single session or task execution. STM is used to store information that is immediately relevant to the current task. It is highly volatile and has limited capacity. For example, during a chat, it ensures the agent remembers the last few messages to respond coherently. Think of this as the RAM (Random access memory) for agents.
Long-term Memory
LTM enables agents to store and retrieve information over extended periods. This allows persistence of knowledge that transcends the context window limitation. LTM implementations typically involve external storage systems such as vector databases, knowledge graphs, or structured databases. These systems allow agents to store information beyond the immediate context window and retrieve it when needed. This comes in handy for a lot of reasons including:
- Retention of information across multiple sessions or tasks
- Ability to learn from past experiences and apply knowledge to new situations
- Support for personalization based on user preferences and history
- Foundation for continuous learning and adaptation
There's a lot of work done in LTM, one that particularly stands out is memgpt. It's authors created their own agent framework letta which is built on the foundations of memgpt.
Different kinds of LTMs
Long-term memory in LLM agents can be conceptualized through three distinct modules, each serving different functions and inspired by human memory systems: semantic, episodic, and procedural memory.
Semantic Memory
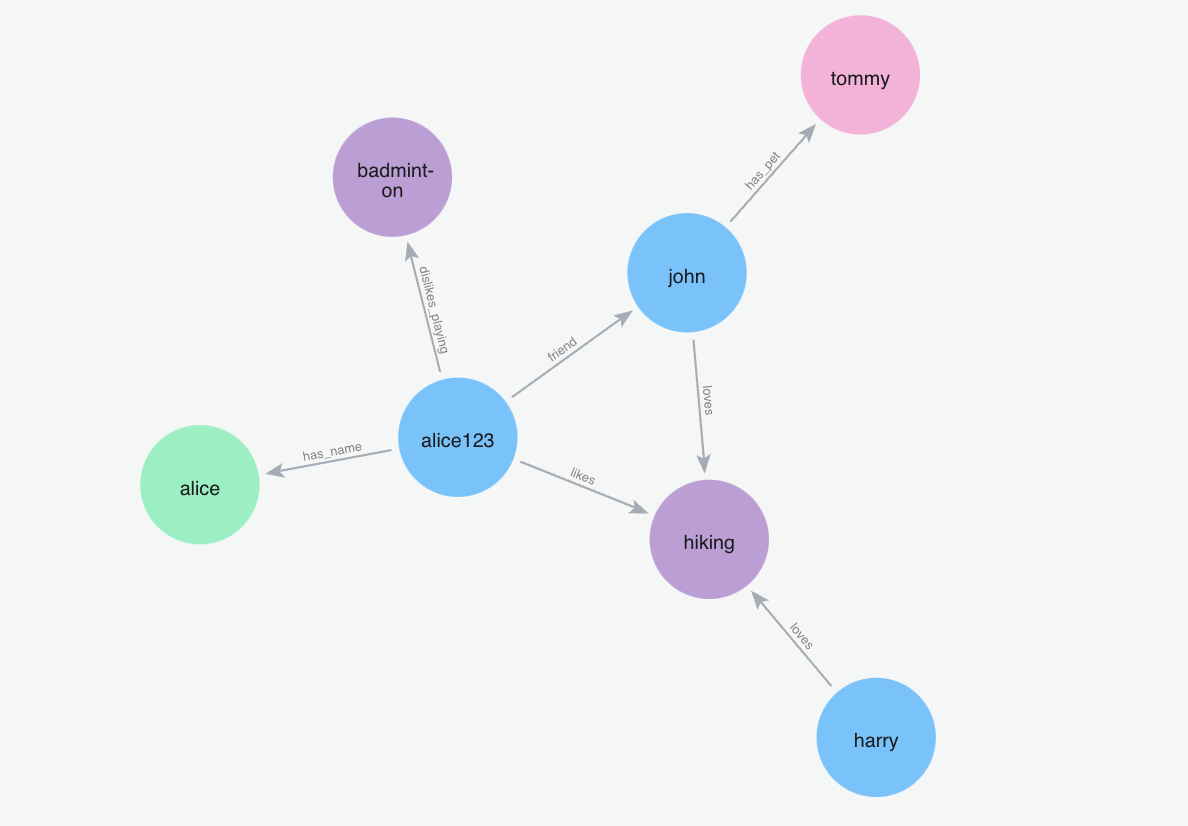
Semantic memory functions as an agent's storage of factual knowledge, concepts, and general understanding about the world. It represents information that isn't tied to specific experiences or events but rather constitutes the agent's accumulated knowledge base.
In LLM agents, semantic memory typically contains:
- Facts and conceptual knowledge
- Definitions and relationships between concepts
- General rules and principles
Implementation approaches for semantic memory often involve structured knowledge bases or vector databases that organize information in ways that facilitate retrieval and reasoning. One common implementation pattern uses embeddings to represent concepts, and retrieving them when necessary. RAG on memory.
The advantage of well-implemented semantic memory is that it allows agents to access relevant knowledge regardless of when or how it was acquired. For example, an agent might incorporate new information about a user's industry and later apply that knowledge in completely different contexts without needing to remember exactly when it learned the information.
We can implement it by passing the past conversation through a LLM and extract relevant information.
Episodic Memory
Episodic memory stores specific events, interactions, and experiences the agent has encountered. While semantic memory might tell an agent what a customer support ticket is in general, episodic memory would contain records of specific tickets the agent has processed including the situation, the thought process that got the agent to that outcome and why did or didn't a specific approach work.
This memory type is crucial for personalization and learning from experience.
CoALA particularly emphasizes episodic memory, stating that it "stores sequences of the agent's past actions." Episodic memories are typically implemented as few-shot examples that the agent can reference to guide its behavior in similar situations.
Procedural Memory
Procedural memory dictates how the agent should behave. It learns and adapts based on user preferences and feedback, essentially evolving the agent's core instructions or "system prompt." If a user prefers a specific email salutation, procedural memory ensures the agent adopts it automatically.
Implementing Memory in Practice
The synergy between short-term and long-term memory is critical, but how and when should information be transferred from one to the other? This is a crucial implementation detail that balances cost, latency, and memory freshness. There are two primary strategies:
1. Real-Time (Synchronous) Updates
In this approach, the LTM is updated after every single interaction. The agent processes the user's message, generates a response, and immediately triggers a memory update process—all before the user sees the final output.
- How it works: User Input -> Agent Response -> LTM Update -> Final Output
- Pros: The agent's long-term memory is always perfectly current. A fact learned in one turn is immediately available for the next.
- Cons: This method introduces significant latency and cost. Each turn requires at least one extra LLM call for memory processing, making the conversation feel slower and more expensive to operate. It can also clutter the LTM with trivial, "noisy" memories that aren't important in the long run.
2. Asynchronous (Batch) Updates
A more efficient and practical approach is to update the LTM in the background. The agent maintains a short-term memory buffer (e.g., the last k turns of the conversation) for immediate context. Once this buffer is full, or when a session concludes, the conversation transcript is sent to a separate, asynchronous process for LTM consolidation.
- How it works: The main conversation thread handles the real-time interaction using only STM. In parallel, a background worker analyzes conversation logs, extracts insights, and updates the semantic, episodic, and procedural LTM databases.
- Pros: This dramatically reduces latency and cost during the live conversation. The agent can respond quickly while a more thoughtful "reflection" process runs in the background, filtering out unimportant details and ensuring only high-signal information is stored.
- Cons: The LTM is not instantly updated. There's a slight delay before new knowledge is consolidated, meaning a fact learned at the very end of one session might not be available in the LTM at the very start of the next.
For most applications, the asynchronous model offers the best balance, creating a responsive user experience while still enabling powerful, long-term learning and evolution
Frameworks for Building Memory
Building these sophisticated memory systems from scratch can be challenging. Fortunately, a growing ecosystem of open-source frameworks is emerging to help developers implement persistent memory for AI agents. These tools provide pre-built components for memory storage, retrieval, and synthesis, abstracting away much of the underlying complexity.
- Mem0: A framework designed to provide self-improving memory for AI agents. It aims to create a "perpetual, evolving memory layer" that allows agents to learn from every interaction.
- LangMem: An SDK from the creators of LangChain, specifically focused on building and managing memory for conversational AI applications. It offers a more structured approach to handling both short-term and long-term memory stores.
- Letta: An agent framework built on the principles of the MemGPT paper (MemGPT: Towards LLMs as Operating Systems). It focuses on creating perpetual chatbots that can manage and reason over their own memory to provide deeply personalized and context-aware conversations.
Conclusion
Memory is super important. We've built agents that remember conversations, learn from experience, and adapt their behavior and not just reset after every interaction.
The three-part system works quite well: semantic memory for facts, episodic for experiences, procedural for evolving behavior. This cognitive architecture is the key to unlocking agents that build a persistent understanding of their world, learn from their successes and failures, and adapt their behavior to serve individual users with increasing fidelity.